
Лучшие инструменты и модели для развёртывания нейросети на домашнем компьютере в 2026 году
Оглавление
Для чего запускать LLM на своём компьютере
Какой инструмент выбрать: LM Studio, Ollama или альтернативы
Базовые термины: токены, параметры, квантование и другие основы
Оценка системных характеристик и расчёт памяти
Актуальные модели 2026 года: полный разбор
Таблица соответствия моделей и железа
Какую модель выбрать под свою задачу
Подробная инструкция по установке и запуску LM Studio
Подробная инструкция по установке и запуску Ollama
Apple Silicon и MLX: отдельный путь для владельцев Mac
Оптимизация: как экономить память, токены и время
Ценные рекомендации и дальнейшие действия
Типичные неполадки и их устранение
Запустить современную большую языковую модель (LLM) — DeepSeek R1, Qwen 3, Llama 3.3 или Gemma 3 — на собственном ПК в 2026 году стало задачей вполне посильной. Открытые модели догнали по качеству платные облачные сервисы, а инструменты для их запуска превратились из набора скриптов в полноценные приложения с интерфейсом «как у ChatGPT». Это руководство проведёт вас от первого скачивания модели до тонкой настройки производительности — с подробным разбором того, какая модель для какой задачи подходит и на каком железе она реально работает.
Мгновенный запуск локальной LLM за 5 минут
Если нужно прямо сейчас развернуть нейросеть без углубления в детали, выбирайте один из двух коротких маршрутов.
Маршрут 1 — графический интерфейс:
- Установите LM Studio с официального сайта.
- В поиске моделей наберите qwen3-8b или llama-3.3-8b.
- Нажмите Download, затем Load Model.
- Переходите в чат и пишите.
Маршрут 2 — командная строка:
ollama run qwen3:8b
Ollama сама скачает модель и откроет интерактивный чат прямо в терминале. Всё, у вас есть локальная нейросеть.
Для чего запускать LLM на своём компьютере
Прежде чем углубляться в технические аспекты, разберём практические причины. Локальное развёртывание даёт ряд преимуществ, которые особенно ощутимы именно в 2026 году.
- Конфиденциальность и безопасность. Вся переписка, документы и код остаются на вашем устройстве. Ничто не уходит на серверы OpenAI, Anthropic или Google. Это критично для работы с коммерческой тайной, медицинскими данными, исходным кодом и личной информацией.
- Полная автономность. Модель работает без интернета. Это особенно актуально в свете нестабильности доступа к сервисам в ряде регионов, включая Россию и часть СНГ.
- Отсутствие платы за токены. После единовременной покупки железа стоимость генерации стремится к нулю — только электричество. Для разработчиков, которые гоняют миллионы токенов в день через автоматические пайплайны, экономия может составлять сотни долларов в месяц.
- Свобода от ограничений и фильтров. Локальные модели не отказывают в темах, не предупреждают и не цензурируют. Это критично для писателей, исследователей и тех, кто работает с ролевыми играми или художественной литературой.
- Возможность дообучения и тонкой настройки. Вы можете адаптировать модель под собственные задачи через файнтюнинг и LoRA-адаптеры, что невозможно с большинством закрытых сервисов.
- Стабильность. Облачные API меняют поведение моделей без предупреждения, отключают версии, поднимают цены. Локальная модель работает ровно так же, как и месяц назад.
Какой инструмент выбрать: LM Studio, Ollama или альтернативы
Перед стартом необходимо определиться с основным инструментом. LM Studio и Ollama остаются двумя наиболее востребованными решениями, но в 2026 году к ним подключились серьёзные альтернативы — Jan и Unsloth Studio.
LM Studio обладает графическим, понятным и интуитивным интерфейсом. Установка происходит через обычный инсталлятор. Программа создана для новичков, дизайнеров, писателей и исследователей. Поиск и загрузка моделей выполняются через интегрированный магазин Hugging Face. Настройка модели осуществляется через ползунки и поля прямо в интерфейсе. В 2026 году LM Studio по умолчанию использует MLX-движок на маках, что даёт прирост скорости на 30–50% по сравнению со старым llama.cpp.
 Сайт LM Studio
Сайт LM Studio
Ollama работает по совершенно иному принципу. Её интерфейс — командная строка, а внутри она представляет собой автоматизированный сервис. Установка происходит через одну команду в терминале или штатный инсталлятор. Также доступен Docker-образ для развёртывания на сервере. Ollama особенно подходит разработчикам, которые встраивают LLM в свои приложения и сценарии. Управление ведётся через команды «ollama pull» и «ollama run». Для тонкой настройки моделей нужны конфигурационные файлы «Modelfile».
 Сайт Ollama
Сайт Ollama
Альтернативы, появившиеся или окрепшие к 2026 году:
- Jan — полноценная замена ChatGPT с открытым исходным кодом, работает полностью офлайн, поддерживает Windows, macOS и Linux. Внутри использует те же модели формата GGUF, что и LM Studio, но с упором на конфиденциальность и расширенную работу с MCP-серверами.
- Unsloth Studio — относительно новое веб-приложение от создателей одноимённой библиотеки. Помимо инференса даёт возможность дообучения моделей прямо из браузера. Особенно хорошо работает с квантованными в их формате Dynamic 2.0 моделями.
- llama.cpp — низкоуровневый движок, на котором построено большинство остальных. Подходит, если нужен максимальный контроль над квантованием, NUMA-тюнингом и сэмплерами. Учитесь работать с командной строкой и компилируете под свою архитектуру.
- vLLM — серверное решение промышленного класса. Имеет смысл, если планируете обслуживать нескольких пользователей одновременно (внутренний инструмент команды, веб-приложение). Батчинг запросов в vLLM на голову бьёт Ollama и llama.cpp.
Краткое резюме выбора:
Базовые термины: токены, параметры, квантование и другие основы
Прежде чем погружаться в требования к железу и выбор моделей, разберём базовый словарь. Эти термины будут встречаться постоянно — и в нашей статье, и в любых других материалах по локальному ИИ. Понимание основ сэкономит часы блужданий по форумам.
Токены — единицы измерения текста
Языковые модели не работают со словами или буквами напрямую. Они работают с токенами — кусочками текста длиной от одного символа до целого слова. Слово «программирование» в токенизаторе Llama может разбиться, например, на «программ», «иро», «вание» — три токена. Короткие частые слова вроде «и», «не», «в» — обычно один токен.
Практические правила, которые стоит запомнить:
- В английском 1 токен ≈ 0,75 слова. То есть «Hello world» — это 2 токена, а абзац из 100 слов — около 130 токенов.
- В русском 1 токен ≈ 0,4–0,5 слова. То есть «Привет мир» — это уже 4–5 токенов, а 100 русских слов — около 200–250 токенов.
- Кириллица токенизируется неэффективно. Одно русское слово часто разбивается на 2–3 токена против одного английского. Это значит, что русский текст «съедает» в 2–2,5 раза больше контекста, чем эквивалентный английский.
- Qwen 3 — лидер по работе с русским. У него токенизатор примерно в 1,5 раза эффективнее для кириллицы, чем у Llama. Если вы много работаете на русском, это серьёзный аргумент в пользу Qwen.
Зачем это знать? Все ограничения и расчёты в мире LLM меряются токенами. Контекст 8K — это 8192 токена, что для русского текста означает примерно 3000–4000 слов или 5–6 страниц A4. Когда вы видите «модель поддерживает контекст 128K», думайте сразу про русский — это не 128K слов, а скорее 50–60K слов.
Параметры — внутренние «веса» модели
Параметр — это одно число внутри нейросети, отвечающее за крошечную часть её знаний. Современные LLM содержат миллиарды таких чисел. Когда вы видите «модель 7B» — это 7 миллиардов параметров.
Каждый параметр в исходном виде хранится как 16-битное число (FP16) и занимает 2 байта. Значит:
- 7B модель в FP16 = 14 ГБ оперативной памяти
- 14B модель в FP16 = 28 ГБ
- 70B модель в FP16 = 140 ГБ — на домашнем ПК нереалистично
Именно поэтому почти никто не использует FP16-версии моделей. Все запускают квантованные варианты (об этом ниже). Чем больше параметров, тем больше «запомненных» фактов и тоньше логические связи. Но это не строгая зависимость: модели Phi от Microsoft показывают, что хорошо обученная 14B-модель может обходить более крупные с худшими тренировочными данными.
Контекстное окно — «оперативная память» модели
Контекстное окно — это сколько токенов модель может одновременно держать в «поле зрения». Сюда входит весь чат, системный промпт, документы, которые вы прикрепили, и сам генерируемый ответ.
Типичные размеры:
- 4K–8K — старые модели, хватает для коротких диалогов
- 32K — комфортно для документов и среднего кода
- 128K–256K — для книг, больших проектов, длинных рассуждений
- 1M–10M — заявленный максимум у Llama 4 Scout, но на практике используется редко
Главный подвох: реальное полезное окно почти всегда меньше заявленного. Большинство моделей начинают «тупеть» после 50% от максимума — забывают середину текста, путают факты, теряют связность. Это называется эффектом «потерянного в середине» (lost in the middle). Не гонитесь за моделями с гигантским контекстом, если вам реально нужно работать с 8–16K.
KV-кэш — невидимый пожиратель памяти
Когда вы общаетесь с моделью, она не пересчитывает всю историю при каждом новом сообщении. Промежуточные вычисления для всех уже виденных токенов сохраняются в KV-кэше — кэше «ключей и значений» механизма внимания.
Чем длиннее разговор, тем больше KV-кэша в памяти. Для модели 14B при 8K контекста KV-кэш занимает примерно 1–2 ГБ. При 128K контекста — уже 8–16 ГБ, иногда больше самой модели. Это причина, почему «у меня раньше всё работало, а после получаса беседы тормозит» — память забилась накопленным контекстом.
Квантование — сжатие модели с минимальными потерями
Уже упоминалось выше, но повторим в общей картине. Квантование — это понижение точности параметров с 16 бит до 8, 6, 5, 4, 3 или даже 2 бит. Это работает, потому что нейросети устойчивы к небольшим ошибкам в весах — модель в целом «умнее» суммы своих параметров.
Стандартный формат файлов с квантованными моделями — GGUF. Его умеют читать llama.cpp, Ollama, LM Studio и почти всё остальное. Альтернативы: EXL2 (быстрее на NVIDIA, но не выдерживает нехватки памяти), AWQ (старый формат для GPU), MLX (формат Apple). Для большинства задач выбирайте GGUF в Q4_K_M — это «золотой стандарт» 2026 года.
Дистилляция — перенос знаний от учителя к ученику
Помните, что DeepSeek R1 в полной версии — это 671B параметров, и запустить его дома нереалистично? Но вы видите варианты DeepSeek-R1-Distill-Qwen-7B, 14B, 32B. Это дистиллированные модели — результат процесса, при котором огромная «учительская» модель обучает меньшую «ученическую».
Как это работает на пальцах: берут полный DeepSeek R1 671B, заставляют его решать тысячи задач с подробными рассуждениями. Эти решения становятся обучающим набором для Qwen 2.5 7B. В итоге Qwen 7B перенимает стиль рассуждений R1, его стратегии решения задач и характерные паттерны мышления — но в размере, который помещается на ноутбук.
Важно понимать: дистиллят — это не «уменьшенная копия» оригинала. Он сохраняет 60–80% способностей в той узкой области, на которой обучался, но не получает все знания учителя. DeepSeek-R1-Distill-Qwen-32B феноменально решает математику и логические задачи, но в общих знаниях о мире уступает родительскому Qwen 2.5 32B.
MoE (Mixture of Experts) — модель из экспертов
Когда вы видите «DeepSeek V3, 671B параметров, 37B активных» — это MoE-архитектура. Модель содержит десятки специализированных «экспертов», и на каждый токен активируется только небольшая часть из них (обычно 2–8 экспертов).
Плюс: качество близко к плотной 671B-модели, а скорость вычислений — как у 37B. Минус: в память надо загрузить все 671B параметров, иначе модель не запустится. MoE экономит вычисления, но не оперативную память.
Практический вывод: MoE-модели — это компромисс для тех, у кого много памяти, но не самое быстрое железо (например, Mac Studio с 192 ГБ единой памяти). На обычной игровой видеокарте с 24 ГБ они работать не будут, даже если параметров «активно» всего 3 ГБ.
Температура, Top P, Top K — управление случайностью
Это параметры сэмплинга — то, как модель выбирает следующий токен из множества вариантов.
- Температура (0–2) — насколько «случайны» ответы. При 0 модель всегда выбирает самый вероятный токен (одинаковые ответы на один и тот же вопрос). При 1 — баланс. При 2 — почти хаос.
- Top P (0–1) — рассматриваются только токены, чья суммарная вероятность не превышает P. Значение 0,9 означает «беру из топа самых вероятных», 1,0 — «беру из всех».
- Top K — рассматриваются только K самых вероятных токенов. 40 — разумно, 1 — жадная декодировка (всегда самое вероятное).
- Repeat Penalty — штраф за повторение токенов, которые уже встречались. 1,0 = выключено. 1,1–1,2 — разумный диапазон против зацикливания.
Конкретные настройки под задачи приведём ниже, в разделе про оптимизацию.
Промпт, системный промпт, инструктивные модели
Промпт — ваш запрос к модели. Системный промпт — постоянная инструкция в начале каждого диалога, задающая «характер» модели («ты эксперт по Python, отвечай кратко»). Системный промпт отправляется с каждым запросом и тоже расходует токены — поэтому имеет смысл писать его сжато.
В названиях моделей часто встречается суффикс Instruct или Chat — это значит, что модель дообучена следовать инструкциям и вести диалог. Версии без этого суффикса (base models) — это «сырые» предобученные модели, они умеют только продолжать текст, и для общения малопригодны. Качайте всегда Instruct-версии, если не занимаетесь файнтюнингом.
Оценка системных характеристик и расчёт памяти
Успешная работа локальной LLM напрямую зависит от конфигурации компьютера, и в первую очередь — от объёма оперативной памяти (RAM) и видеопамяти (VRAM). Основное правило: модель должна полностью помещаться в память, иначе скорость рухнет в 5–30 раз из-за выгрузки слоёв на жёсткий диск.
Размер моделей обычно указывается цифрой с буквой B. Например, 7B означает 7 миллиардов параметров. Чем больше параметров, тем умнее модель, но и тем больше памяти нужно. Современным «середняком» считаются модели 14–32B.
Что такое квантование и почему оно важно
Модель в исходном виде хранит каждый параметр как 16-битное число (FP16) — это около 2 ГБ на каждый миллиард параметров. Для модели Llama 3.3 70B это означает 140 ГБ оперативной памяти, что нереалистично для домашнего ПК.
Квантование — это сжатие модели с понижением точности параметров. Стандартом 2026 года стал формат Q4_K_M (4-битное квантование), который сжимает модель в четыре раза с минимальной потерей качества — обычно менее 2% на типовых задачах.
Простая формула для оценки нужного объёма памяти при Q4_K_M квантовании: размер модели в ГБ ≈ количество параметров в B × 0,6. Плюс заложите 2–4 ГБ на контекст и системные нужды.
Ориентировочные требования для моделей разного объёма
- Модели 1B–3B требуют минимум 4 ГБ ОЗУ и 1–3 ГБ на диске. Подходят для смартфонов, ноутбуков на батарее, простых ботов и автодополнения текста.
- Модели 7B–9B требуют 8–10 ГБ ОЗУ и 4–6 ГБ на диске. Это рабочая лошадка: универсальный чат, помощь с кодом, переводы, простые задачи рерайтинга.
- Модели 12B–14B требуют 12–16 ГБ ОЗУ и 7–9 ГБ на диске. Существенный скачок качества: сложные рассуждения, аналитика, развёрнутые тексты.
- Модели 22B–32B требуют 24–32 ГБ ОЗУ и 13–20 ГБ на диске. Уровень, на котором локальные модели начинают всерьёз конкурировать с облачными ChatGPT и Claude.
- Модели 70B+ требуют 48–64 ГБ ОЗУ и 40–48 ГБ на диске. Сравнимы с топовыми коммерческими решениями, но запускаются только на серьёзном железе.
- Гигантские модели уровня DeepSeek V3/V4 (671B–1T) требуют от 350 ГБ оперативной памяти. На домашнем ПК нереалистично, нужен сервер с несколькими H100 или мощный Mac Studio M3 Ultra с 256–512 ГБ единой памяти.
Актуальные модели 2026 года: полный разбор
В 2026 году ландшафт открытых моделей сложился вокруг шести крупных семейств. Каждое имеет свои сильные стороны, и слепо хватать «самую популярную» — путь к разочарованию. Разберём, кто за что отвечает.
Qwen 3 — лидер по программированию и многоязычности
Семейство от Alibaba стало главной открытой моделью 2026 года по статистике скачиваний Hugging Face. Доступно множество размеров: 0,5B, 1,5B, 3B, 4B, 7B, 8B, 14B, 32B, 72B и гигантский MoE-вариант 235B-A22B.
- Сильные стороны: лучшая поддержка многих языков, включая русский и китайский. Уверенный тулколлинг (вызов функций). Гибридный режим: можно включать «рассуждения», как у DeepSeek R1, или отключать для быстрых ответов. Поддержка контекста до 256K токенов.
- Слабые стороны: 14B и крупнее иногда «уходит в петлю» рассуждений, если не подкрутить параметры сэмплинга.
- Когда выбирать: универсальный помощник, перевод и работа на русском, программирование, агентные сценарии.
Отдельно стоит упомянуть Qwen 2.5 Coder и более новый Qwen 3 Coder Next — специализированные версии для программирования. Qwen 2.5 Coder 32B в HumanEval показывает около 85%, что выше уровня большинства закрытых моделей предыдущего поколения. Qwen 3 Coder Next — это 80B MoE-модель с 3B активных параметров: при 46 ГБ оперативной памяти даёт уровень моделей в 10–20 раз большего размера.
Llama 3.3 — универсальный солдат от Meta
Llama 3.3 в варианте 8B остаётся лучшим универсальным выбором для слабого железа. Версия 70B — конкурент топовым коммерческим моделям на задачах общего профиля.
- Сильные стороны: огромное сообщество и сотни файнтюнов под любые задачи — от медицины (OpenBioLLM) до творческого письма (Euryale, Hermes, Dolphin). Лучшая поддержка инструментов в экосистеме (LangChain, LlamaIndex). Поведение модели предсказуемо.
- Слабые стороны: в коде уступает Qwen, в рассуждениях — DeepSeek R1. Лицензионные ограничения на коммерческое использование (свыше 700 миллионов активных пользователей в месяц).
- Когда выбирать: общий чат, написание текстов, ассистент по работе, если нужен сторонний файнтюн под конкретную задачу.
DeepSeek R1 и его дистилляты — король рассуждений
DeepSeek R1 произвёл революцию в открытом ИИ в январе 2025 года. Полная модель — 671B параметров в MoE-архитектуре с 37B активных, обучена примерно за 6 миллионов долларов. На домашнем ПК запустить полную версию нереалистично, но команда DeepSeek выпустила «дистиллированные» версии, перенесённые на меньшие модели семейств Qwen и Llama.
Главная фишка R1 — видимая цепочка рассуждений в тегах <think>. Вы буквально наблюдаете, как модель думает, проверяет себя, ловит ошибки и переписывает решение. Для математики, логических задач и отладки кода это меняет правила игры.
Gemma 3 — компактный мультимодальный лидер от Google
Gemma 3 доступна в размерах 1B, 4B, 12B и 27B. Главная особенность — нативная мультимодальность: модели 4B и крупнее принимают на вход не только текст, но и изображения. Контекст — до 128K токенов.
- Сильные стороны: отличная работа на относительно слабом железе. Gemma 3 27B при Q4 квантовании запускается на одной RTX 4090. Сильная поддержка более ста языков. Хорошо понимает изображения — можно показать график или скриншот и получить разбор.
- Слабые стороны: уступает Qwen 3 в программировании. Менее предсказуемый стиль ответов в творческих задачах.
- Когда выбирать: когда нужна работа с картинками, многоязычный ассистент, аналитика документов с графиками.
Phi-4 — компактная мощь от Microsoft
Семейство Phi от Microsoft славится тем, что выжимает из малых моделей качество, сравнимое с моделями в 3–5 раз большего размера. В 2026 году актуальны Phi-4-mini (3,8B) и Phi-4 (14B).
- Сильные стороны: Phi-4 14B обходит даже GPT-4o на бенчмарках по математике (MATH) и научных вопросах уровня выпускника университета (GPQA). Лидер плотности качества на параметр.
- Слабые стороны: слабее в творческих задачах и многоязычности. Узкий контекст по сравнению с Qwen 3 — 16K токенов в Phi-4-mini.
- Когда выбирать: математика, наука, технические задачи на железе с ограничениями, образование.
Mistral Small 3 и Mixtral — скорость и инструкции
Французская Mistral AI выпустила в 2026 году Mistral Small 3 — плотную модель на 7B, заточенную под скорость инференса. Также актуален Mixtral 8x7B в формате MoE для тех, у кого есть 32–48 ГБ памяти.
- Сильные стороны: ~50 токенов в секунду на скромном железе. Дисциплинированное следование инструкциям. Apache 2.0 лицензия — можно использовать в коммерции без ограничений.
- Слабые стороны: уступает Qwen 3 и Llama 3.3 в качестве ответов на длинных контекстах.
- Когда выбирать: когда важна скорость генерации (стриминговые ответы, голосовые помощники) или строгое следование формату вывода (JSON, структурированные данные).
Творческие и ролевые модели — отдельная вселенная
Для писателей, ролевиков и тех, кто работает с художественной литературой, существует целая экосистема файнтюнов. Они построены на базе Llama 3.3, Qwen 2.5 или Gemma, но дообучены на специальных датасетах для творчества.
- Llama 3.3 70B Euryale v2.3 — золотой стандарт для серьёзного художественного письма и сложных ролевых сценариев. Богатый словарь, чувство стиля, длинные осмысленные сцены.
- EVA Qwen 2.5 в размерах 7B, 14B и 32B — оптимизирована под ролевые игры, имеет минимальные ограничения, доступна в дистиллированных вариантах для слабого железа.
- Tiger Gemma 9B v3 — отлично передаёт диалоги и эмоциональные сцены, при этом компактна.
- Llama 3.1 8B Lexi Uncensored V2 — для брейншторминга и обсуждения тем, которых избегают базовые модели.
- Dolphin 2.9 Llama 3 8B — универсальный uncensored файнтюн с упором на ассистентские задачи.
Топовые модели для энтузиастов и серверов
Если у вас сервер с несколькими видеокартами или Mac Studio M3 Ultra с 192–512 ГБ единой памяти, открывается доступ к моделям нового уровня.
- Llama 4 Scout (109B общих параметров, 17B активных, MoE) — лидер по длине контекста (10 миллионов токенов). Помещается на одну H100 80GB при INT4 квантовании.
- DeepSeek V3.2 и V4 (671B–1T параметров) — топ открытых reasoning-моделей на математике и многошаговых задачах. Требуют от 700 ГБ памяти.
- Qwen3-Coder-Next (80B, 3B активных) — лучшая открытая модель для агентного кодинга в 2026 году по консенсусу сообщества. Запускается на 46 ГБ памяти.
- GLM-5.1 от Zhipu AI — MoE-модель с 744B параметров (40B активных), сильна в тулколлинге и агентных сценариях.
- Kimi K2.6 — 1,1T параметров, специализация на длинных автономных рабочих процессах разработки.
Таблица соответствия моделей и железа
Ниже — практическая шпаргалка, какая модель куда влезает. Все цифры приведены для квантования Q4_K_M, которое в 2026 году считается оптимальным компромиссом между качеством и размером.
Какую модель выбрать под свою задачу
Чтобы окончательно расставить точки над i, ниже — практическая матрица «задача → модель → железо». Это поможет не тратить часы на скачивание и тестирование наугад.
Подробная инструкция по установке и запуску LM Studio
Сейчас разберём установку и запуск обеих главных программ. Установка LM Studio проходит легко и интуитивно даже для начинающих благодаря графическому интерфейсу.
Зайдите на официальный сайт lmstudio.ai и скачайте версию для своей операционной системы: Windows, macOS или Linux. Запустите инсталлятор и следуйте указаниям. После установки запустите приложение.
 Окно скачивания LM Studio на Mac
Окно скачивания LM Studio на Mac
LM Studio по умолчанию ищет модели на платформе Hugging Face, доступ к которой ограничен в России и СНГ. Для ускорения работы и обхода блокировок рекомендуется настроить зеркало:
- Закройте LM Studio.
- Найдите папку с установленной программой.
- С помощью текстового редактора (например, «Блокнот» или VS Code) откройте файлы с расширением .js.
- Во всех файлах найдите строку huggingface.co и замените её на hf-mirror.com.
- Сохраните изменения и перезапустите LM Studio.
Альтернативный вариант — использовать VPN на время скачивания моделей. После того как модели лежат локально, интернет для работы не нужен.
 Интерфейс Hugging Face
Интерфейс Hugging Face
В левом меню нажмите на значок поиска (лупа), чтобы перейти на вкладку Discover или Model Search. В поисковой строке введите наименование модели, например, qwen3-14b-instruct или deepseek-r1-distill-qwen-14b. Вы увидите перечень доступных файлов в формате .gguf. Обратите внимание на колонку с размером файла и степенью квантования, например, Q4_K_M. Нажмите Download для загрузки.
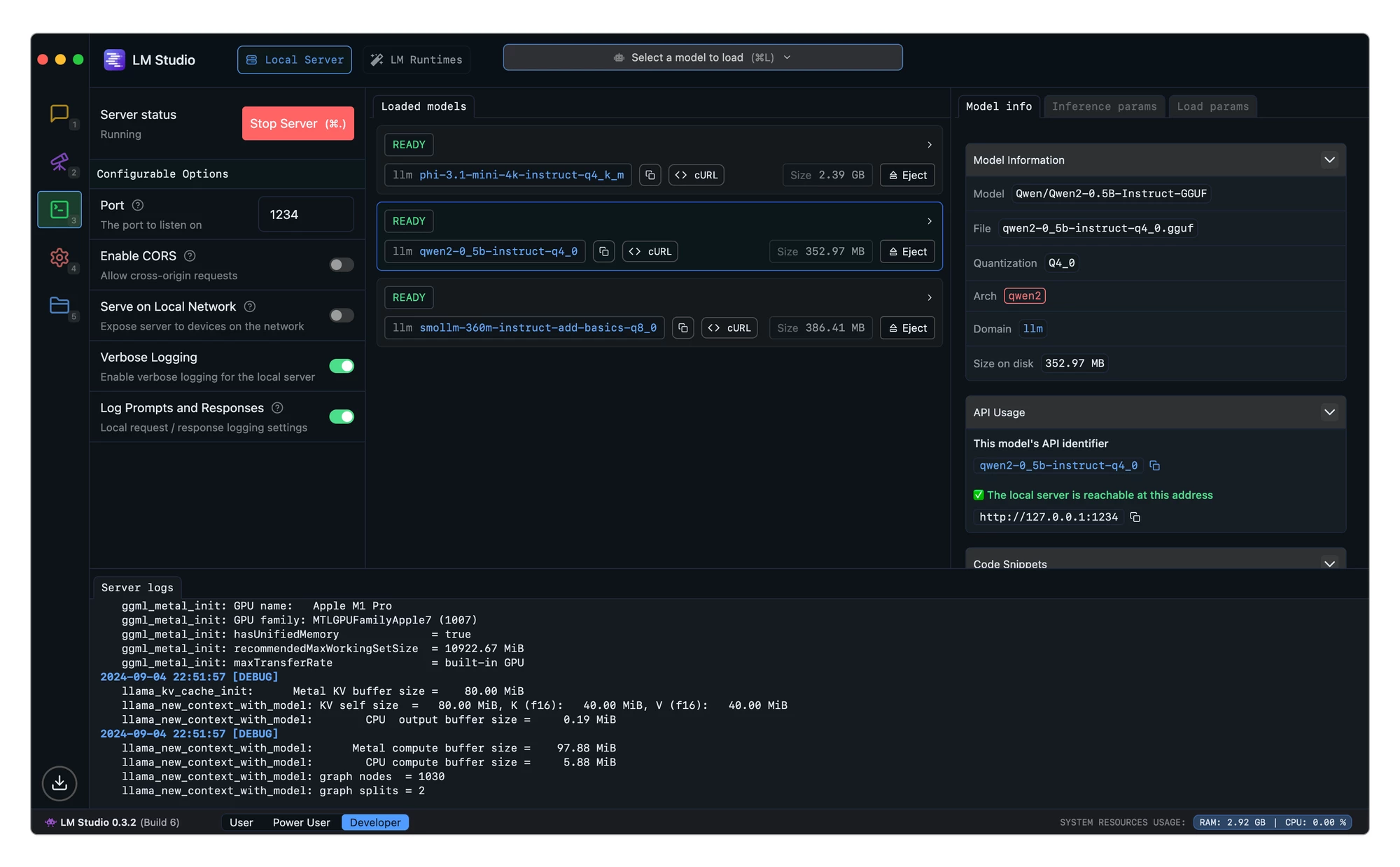 Окно поиска модели в LM Studio
Окно поиска модели в LM Studio
После завершения загрузки перейдите на вкладку Chat. В выпадающем меню в верхней части экрана выберите загруженную модель. Нажмите кнопку Load Model. Когда модель будет загружена в память, строка состояния станет активной. Теперь можно общаться с моделью.
Полезные настройки в правой панели:
- GPU Offload — сколько слоёв модели выгрузить на видеокарту. Чем больше, тем быстрее, но требует больше VRAM. На современных видеокартах смело ставьте на максимум.
- Context Length — длина контекста. Большее значение = больше памяти. 8K хватает для чата, 32K — для документов, 128K и выше — для книг.
- Temperature — креативность. 0,7 для творчества, 0,2–0,3 для кода и фактов.
- Top P / Top K — параметры сэмплинга. Если модель уходит в петлю, поднимите Top P до 0,95.
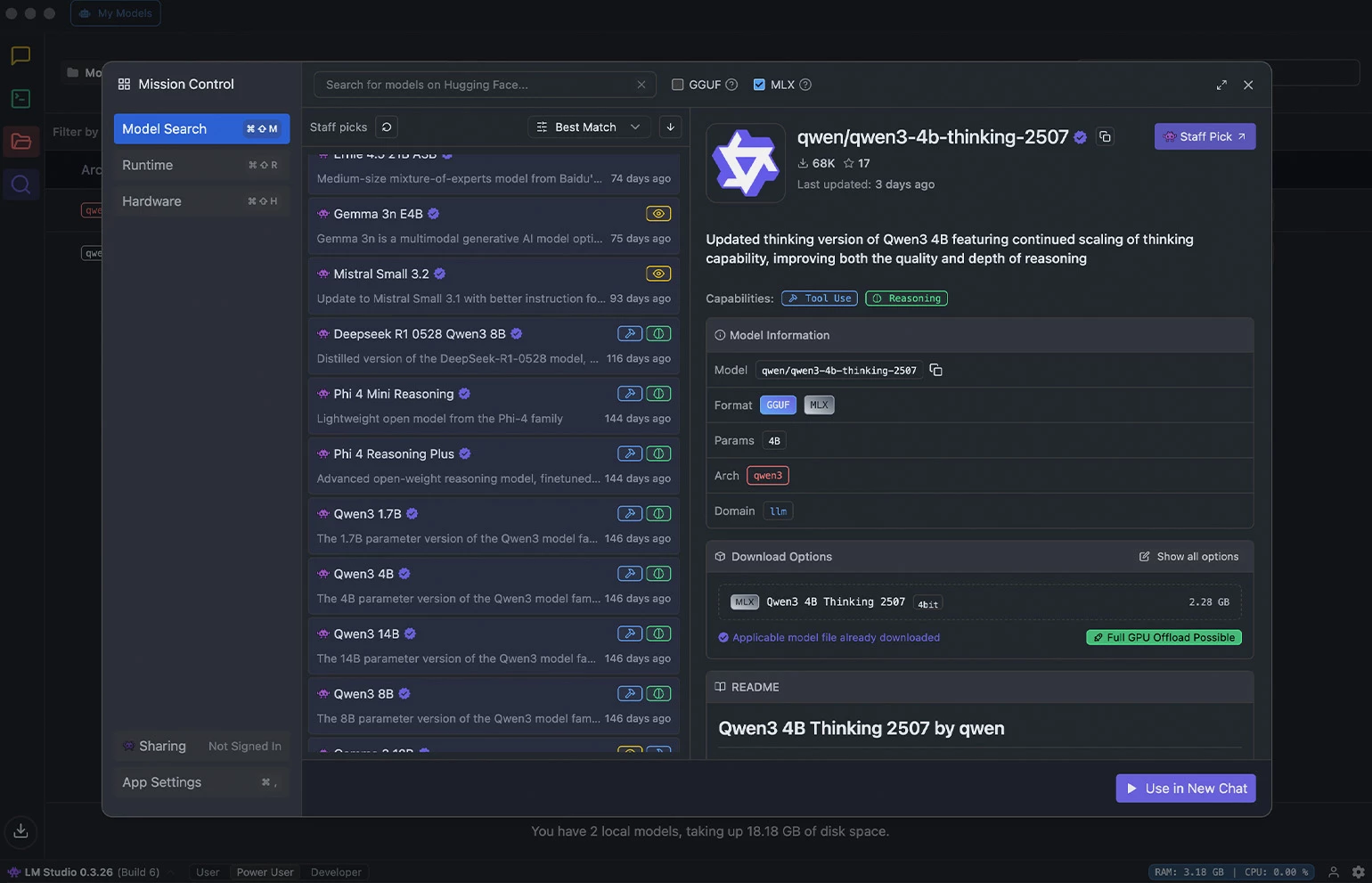 Интерфейс LM Studio
Интерфейс LM Studio
Подробная инструкция по установке и запуску Ollama
Установка Ollama несколько сложнее, поскольку требует работы с терминалом, но взамен предлагает больше возможностей и позволяет встроить LLM непосредственно в свой сервис или скрипт.
Наиболее простой способ установки для пользователей macOS и Linux — выполнить в терминале одну команду:
curl -fsSL https://ollama.com/install.sh | sh
Пользователям Windows нужно скачать и запустить установщик .exe с официального сайта ollama.com. После установки проверьте версию:
ollama --version
 Окно загрузки Ollama на Windows
Окно загрузки Ollama на Windows
Ollama работает с готовыми образами моделей. Чтобы загрузить и сразу запустить модель, выполните команду:
ollama run qwen3:14b
или для модели рассуждений:
ollama run deepseek-r1:14b
Ollama автоматически скачает подходящую версию модели и откроет интерактивный чат прямо в терминале. Если нужно только загрузить модель без запуска, используйте команду ollama pull.
Полезные команды для управления:
После загрузки модели Ollama автоматически запускает локальный API-сервер, который по умолчанию доступен по адресу http://localhost:11434. Этот сервер совместим с API OpenAI, что позволяет подключать любые библиотеки и инструменты, написанные под ChatGPT.
Пример простого запроса через curl:
curl http://localhost:11434/api/generate -d '{"model": "qwen3:14b", "prompt": "Расскажи о Казахстане"}'
Для тонкой настройки модели Ollama использует файлы Modelfile. Это аналог Dockerfile, но для языковых моделей. Пример:
FROM qwen3:14b
PARAMETER temperature 0.3
PARAMETER num_ctx 16384
PARAMETER num_gpu 99
SYSTEM "Ты помощник по программированию на Go. Отвечай кратко и по делу."
Сохраните файл как Modelfile, затем создайте свою версию модели:
ollama create my-coder -f Modelfile
ollama run my-coder
Apple Silicon и MLX: отдельный путь для владельцев Mac
Маки на чипах M1, M2, M3 и M4 за последние пару лет превратились в один из лучших инструментов для запуска локальных LLM — и не из-за «волшебной» Apple-производительности, а благодаря архитектуре единой памяти (Unified Memory).
Почему Mac хорош для локальных моделей
На обычном ПК у видеокарты своя память (VRAM), и модель должна туда полностью поместиться, иначе всё работает в десятки раз медленнее. Самая дорогая потребительская видеокарта, RTX 5090, имеет 32 ГБ VRAM. Модель Llama 3.3 70B в Q4 — это 43 ГБ, она туда не влезет полностью.
На маках процессор, видеоядро и нейроядро делят один общий пул памяти. MacBook Pro M4 Max с 64 ГБ единой памяти спокойно загружает 70B-модель целиком и работает с ней с полным GPU-ускорением. Это невозможно ни на одной потребительской видеокарте без покупки двух RTX 4090 или специальной про-карты за тысячи долларов.
Минус — пропускная способность памяти на маках ниже, чем у дискретных видеокарт. M4 Max выдаёт 546 ГБ/с, а RTX 4090 — около 1000 ГБ/с. Поэтому маки медленнее в тех сценариях, где модель помещается на видеокарту, но непобедимы, когда речь идёт о крупных моделях.
Выбор Mac под локальные LLM в 2026
MLX — секретный ускоритель для Mac
Если вы запускаете модели на маке через Ollama со стандартным движком llama.cpp, вы теряете 30–50% скорости. MLX — это машиннообучающий фреймворк Apple, оптимизированный исключительно под архитектуру M-серии и Metal API.
Конкретные цифры разницы между llama.cpp и MLX:
- На 70B-модели на M4 Max — 15 ток/с против 22 ток/с. Разница между «терпимо» и «комфортно».
- На некоторых конфигурациях Qwen 3 32B — до 2,5× прироста.
- На малых моделях вроде Phi-4-mini на M5 Max через MLX достигается ~140 ток/с.
В 2026 году LM Studio переключилась на MLX по умолчанию на маках — это самый простой способ получить ускорение. Для командной строки есть пакет mlx-lm:
pip install mlx-lm
python -m mlx_lm.generate --model mlx-community/Qwen3-14B-Instruct-4bit --prompt "Привет"
Если вы используете Ollama на маке, имейте в виду: для большинства моделей переход на LM Studio с MLX или прямой запуск через mlx-lm даст видимый прирост без всяких новых видеокарт.
Оптимизация: как экономить память, токены и время
Запустить модель — половина дела. Чтобы она работала быстро, не съедала всю память и давала качественные ответы, нужно понимать ещё несколько практических вещей. Этот раздел — для тех, кто уже погонял локальную LLM пару недель и хочет выжать из неё максимум.
Когда пора начинать новый диалог
В отличие от облачных сервисов, где «новый чат» — это просто привычка, в локальной LLM каждое сообщение в длинном диалоге замедляет работу и съедает память. Признаки, что пора нажать «новый чат»:
- Контекст близок к лимиту модели. В LM Studio счётчик токенов виден в нижней панели — если он показывает 7800 из 8192, дальше будут проблемы. В Ollama проверьте через ollama ps, сколько контекста занято.
- Сменилась тема. Если только что вы обсуждали Python, а теперь хотите перевести стихотворение — старый контекст не помогает, а только тратит ресурсы. Дешевле начать заново.
- Качество ответов снижается. Модель путает имена, забывает, что обсуждалось 20 сообщений назад, теряет нить рассуждений. Это первый признак, что контекст перегружен.
- Модель начала повторяться или зацикливаться. Иногда это лечится повышением Repeat Penalty, но чаще — началом нового чата.
- Скорость генерации заметно упала. Если первый ответ шёл со скоростью 40 токенов в секунду, а после получаса беседы — 8 токенов в секунду, значит KV-кэш забил всю свободную память.
Полезное правило: для творческих задач (написание текста, мозговой штурм) — новый чат раз в 10–15 сообщений. Для технических консультаций — можно тянуть длиннее, если тема одна. Для отладки кода — лучше отдельный чат на каждую проблему.
Как считать токены до отправки
Не всегда есть желание считать токены вручную, но базовое чутьё помогает планировать длину запросов:
- В Ollama флаг --verbose показывает использованные токены после каждого ответа.
- В LM Studio счётчик токенов висит постоянно в нижней панели чата.
- Грубая оценка: одно русское слово ≈ 2 токена, одно английское слово ≈ 1,3 токена.
- Один абзац (50–100 слов) — это 100–200 токенов.
- Страница A4 текста — это около 600–800 токенов на русском или 400–500 на английском.
- Большой PDF-документ (50 страниц) — это 30–40K токенов, что близко к лимиту многих моделей.
Длина контекста: как она влияет на всё
Многие пользователи по умолчанию выставляют максимальный контекст «на всякий случай» и удивляются, почему модель тормозит. На самом деле длина контекста влияет на три вещи:
Практическое правило для большинства задач:
- 8K — короткие диалоги, программистский ассистент, переводы, рерайт. Самый быстрый режим.
- 16K–32K — работа с документами, анализ кода в репозиториях, длинные обсуждения. Золотой стандарт для повседневной работы.
- 128K и больше — анализ книг, объёмных научных статей, юридических документов. Используйте только когда реально надо.
Оптимизация на уровне промпта
Самая большая утечка токенов — раздутые системные промпты и привычка вставлять в чат полные документы. Что делать:
- Сжимайте системный промпт. Каждое слово в нём отправляется с каждым запросом. «Ты эксперт по Python, отвечай кратко» — хороший промпт. Развёрнутые инструкции на 500 слов с примерами — расточительство, если вы общаетесь с моделью часами.
- Не вставляйте документы целиком. Если нужен ответ по PDF на 100 страниц — используйте RAG (через AnythingLLM или Open WebUI), который найдёт релевантные куски. Иначе вы каждый запрос платите токенами за всю книгу.
- Удаляйте устаревшие сообщения. В большинстве UI можно стереть или отредактировать любое сообщение из истории. Если в начале диалога была черновая версия кода, которая больше не нужна — уберите её, освободите контекст.
- Используйте Modelfile для повторяющихся задач. Если каждый день запускаете модель с одним и тем же системным промптом — оформите его как Modelfile в Ollama. Это работает быстрее и удобнее, чем копировать вручную.
Параметры сэмплинга для разных задач
«Какой ставить temperature?» — один из самых частых вопросов. Универсального ответа нет, но есть проверенные пресеты:
Важное замечание: для рассуждающих моделей вроде DeepSeek R1 не задирайте температуру — это ломает цепочку рассуждений. Их разработчики прямо рекомендуют 0,6.
Промпт-кэширование: невидимое ускорение
Современные движки умеют кэшировать KV-вычисления для повторяющихся префиксов. Если вы используете один и тот же большой системный промпт каждый раз, он считается один раз — а потом просто переиспользуется.
Поддержка кэширования в 2026 году:
- Ollama — кэширование префиксов включено по умолчанию в свежих версиях.
- LM Studio — поддерживает с версии 0.3.x, проверяйте в настройках Server.
- vLLM — самая агрессивная поддержка, ускоряет повторные запросы в 5–10 раз.
- llama.cpp — флаг --prompt-cache сохраняет кэш на диск между запусками.
Практическое следствие: если у вас длинный системный промпт, он замедлит только первый запрос. Последующие будут лететь.
Когда уменьшить, а когда увеличить модель
Все хотят запустить самую большую модель, которая влезет в железо. Это не всегда правильно. Сигналы, что модель слишком большая для задачи:
- Простые запросы (форматирование, короткий перевод) обрабатываются по 5–10 секунд
- Скорость генерации меньше 10 токенов в секунду — пользоваться некомфортно
- Жёсткий диск активно работает во время ответов (это значит, что модель частично выгружается на SSD)
- Качество ответов на простых задачах не отличается от модели поменьше
В этих случаях имеет смысл переключиться на модель в 2 раза меньше — пользоваться станет в 4 раза быстрее, а разницу в качестве вы вряд ли заметите.
Сигналы, что модель слишком мала для задачи:
- Модель регулярно ошибается в логике и фактах
- В коде появляются синтаксические ошибки и галлюцинации API
- Длинные тексты теряют связность и структуру
- Модель не понимает многоступенчатые инструкции
В этих случаях нужна модель крупнее или специализированная под задачу — например, Qwen 2.5 Coder вместо общего Llama 3.3, или DeepSeek-R1-Distill вместо обычного Qwen.
GPU offload: правильная настройка
В LM Studio и Ollama есть параметр num_gpu или GPU Offload Layers — сколько слоёв модели выгрузить на видеокарту. По умолчанию инструменты подбирают значение автоматически, но иногда стоит вмешаться:
- Если вся модель помещается в VRAM — ставьте максимум (99 или -1, что означает «все слои»). Это даёт максимальную скорость.
- Если модель чуть не помещается — попробуйте уменьшить контекст, прежде чем снижать GPU offload. Контекст ест меньше, чем веса модели.
- Если модель сильно больше VRAM — выгрузите столько слоёв, сколько помещается, остальное останется на CPU. Скорость упадёт, но модель запустится.
- Если у вас несколько GPU — Ollama и LM Studio умеют делить модель между ними. Проверьте через nvidia-smi, что все карты загружены.
Бенчмарк-пример с реального RTX 4060 8GB на модели Qwen 3 8B Q4_K_M при контексте 16K: полная выгрузка на GPU даёт 40,58 ток/с, частичная (25 из 36 слоёв) — 8,62 ток/с. Разница почти в 5 раз. Старайтесь не дробить, если есть выбор.
Стриминг и время до первого токена (TTFT)
Есть два показателя скорости, и они важны по-разному:
- TTFT (Time To First Token) — задержка перед началом ответа. Это время на обработку всего вашего запроса и формирование первого токена. На длинных промптах может занимать секунды.
- Throughput — скорость генерации токенов после старта (те самые «токены в секунду»).
Для интерактивного общения важнее TTFT — никто не любит ждать 10 секунд до начала ответа. Для пакетной обработки (генерация 1000 текстов скриптом) важнее throughput. Если вы видите низкий TTFT — оптимизируйте длину промпта и используйте промпт-кэширование. Если низкий throughput — берите модель поменьше или квантование агрессивнее.
Стриминг — это режим, при котором ответ возвращается по токенам, а не всем куском. В LM Studio и Ollama он включён по умолчанию. В кастомных скриптах через API не забудьте параметр stream: true — иначе будете ждать полного ответа, и это будет ощущаться очень долго.
Ценные рекомендации и дальнейшие действия
У LM Studio и Ollama есть дополнительные возможности, которые делают их частью полноценной инфраструктуры локального ИИ.
API-сервер и подключение к внешним приложениям
Обе программы включают встроенный сервер, имитирующий API OpenAI. Это даёт возможность подключить локальную LLM к любому приложению, которое умеет работать с ChatGPT. Порты по умолчанию:
- LM Studio — http://localhost:1234
- Ollama — http://localhost:11434
Что можно к этому подключить:
- Continue, Cline, Roo Code — расширения для VS Code, которые превращают локальную модель в полноценного программного помощника с подсветкой, автодополнением и рефакторингом.
- Open WebUI — веб-интерфейс в духе ChatGPT для удобного общения через браузер, с историей чатов и сохранением промптов.
- AnythingLLM — позволяет загружать собственные документы и работать с RAG (поиск по своим файлам), что особенно ценно для исследователей.
- Cherry Studio — продвинутый клиент с поддержкой нескольких моделей одновременно и работой с агентами.
- Go-библиотека sashabaranov/go-openai — для интеграции в свои Go-приложения. Достаточно поменять BaseURL на адрес локального сервера.
 AnythingLLM
AnythingLLM
RAG: давайте модели свои документы
Любая локальная модель «знает» только то, на чём её обучали, и не в курсе ваших файлов. Технология RAG (Retrieval-Augmented Generation) решает это: вы загружаете свои документы, они векторизуются, и при вопросе модель сначала находит релевантные куски, а потом отвечает на их основе.
Самые простые пути попробовать RAG:
- AnythingLLM — встроенная поддержка PDF, DOCX, веб-страниц. Подключается к Ollama или LM Studio через API.
- Open WebUI — поддерживает загрузку файлов прямо в чат через кнопку «прикрепить».
- LlamaIndex — библиотека Python для более тонкой настройки RAG со своей логикой.
Используйте GPU и квантование с умом
По возможности используйте видеокарту. Она обрабатывает запросы значительно быстрее центрального процессора — разница может быть в десятки раз. На голом CPU модель будет работать, но генерировать всего 2–8 токенов в секунду, что некомфортно для интерактивной работы.
На квантовании не экономьте. Лучше взять модель размером поменьше с Q4_K_M или Q5_K_M, чем большую модель с Q2_K. Квантование ниже Q3 заметно бьёт по способности к рассуждениям и кодированию.
Совет от практиков
Бывший директор по ИИ в Tesla Андрей Карпати неоднократно отмечал, что архитектура единой памяти Apple идеально подходит для персонального использования LLM. ML-исследователь Себастьян Рашка ежедневно использует Mac Mini M4 Pro для локального инференса с Ollama, регулярно запуская 20B-модели на ~45 токенов в секунду. При этом он подчёркивает: дообучение и тренировку всё равно лучше делать на CUDA-железе. Это разумное разделение: маки для инференса, NVIDIA для тренировки.
Типичные неполадки и их устранение
Разберём, какие проблемы могут возникнуть при работе с локальными LLM и как их решать.
Не хватает памяти, модель не загружается
Выберите модель с более высокой степенью квантования (Q3_K_M или Q4_K_S вместо Q4_K_M). Закройте все ресурсоёмкие программы — особенно браузер с десятками вкладок и игры. Уменьшите длину контекста: с 32K до 8K часто высвобождает 2–4 ГБ.
Модель отвечает медленно или зависает
Почти всегда это нехватка вычислительных ресурсов. Проверьте через диспетчер задач, не выгружается ли модель в файл подкачки. Если да — берите модель поменьше. В LM Studio включите GPU offloading на максимум и увеличьте количество потоков процессора в настройках Performance. В Ollama проверьте через ollama ps, что модель работает на 100% GPU, а не на CPU+GPU.
Видеокарта не используется
На Windows убедитесь, что установлены последние драйверы NVIDIA или AMD. Ollama и LM Studio должны определить видеокарту автоматически. Проверьте через ollama run llama3 --verbose, на каком устройстве работает модель — там будет указано «using CUDA» или «using CPU».
На Linux может понадобиться установка пакетов CUDA Toolkit или ROCm (для AMD). На macOS Metal-ускорение работает из коробки.
Файл модели повреждён или модель ведёт себя странно
Удалите модель и скачайте заново. Проверьте, что путь к файлу не содержит кириллических символов и пробелов — это до сих пор регулярно ломает llama.cpp на Windows. Если модель «уходит в петлю» или повторяет одно и то же, поднимите параметр Repeat Penalty до 1,15–1,2 и Top P до 0,95.
API не отвечает
Проверьте, запущен ли сервер. В LM Studio он включается вручную на вкладке Developer кнопкой Start Server. В Ollama сервер запускается автоматически при первой команде. Убедитесь, что порт (1234 или 11434) не блокирует брандмауэр Windows или firewall Linux. Если работаете в Docker — пробросьте порт наружу через флаг -p 11434:11434.
DeepSeek R1 показывает странные теги <think>
Это нормально — так и должно быть. Модель сначала пишет цепочку рассуждений в этих тегах, а потом — финальный ответ. Большинство интерфейсов (LM Studio свежих версий, Open WebUI, Jan) сворачивают этот блок автоматически. Если используете API напрямую, отфильтруйте содержимое между <think> и </think> на стороне приложения.
Модель не отвечает на русском
Не все модели одинаково хороши в русском. Лидеры — семейство Qwen 3 (особенно 14B и старше), а также крупные Llama 3.3. Phi-4, Gemma и Mistral на русском говорят, но с заметными артефактами. Если модель упорно отвечает по-английски, добавьте в системный промпт «Always respond in Russian unless explicitly asked otherwise».
Итог
В 2026 году запуск локальной LLM перестал быть нишевым увлечением. Хорошая открытая модель уровня Qwen 3 14B или Llama 3.3 8B работает на любом современном ноутбуке с 16 ГБ оперативной памяти и заменяет 80% запросов, которые раньше уходили в платный ChatGPT. Mac Mini M4 Pro за условные 1800 долларов превращается в персональный AI-сервер с возможностями, доступными ещё пару лет назад только в облаке за сотни долларов в месяц.
Начните с малого: установите LM Studio, скачайте Qwen 3 8B в Q4_K_M, погоняйте на своих задачах. Затем масштабируйтесь под свои сценарии — кодинг через Qwen 2.5 Coder, рассуждения через DeepSeek R1 Distill, творчество через Llama 3.3 Euryale, многоязычие через старшие Qwen. Локальный ИИ — это не только конфиденциальность и экономия, но и независимость от чужих серверов и политик. Это инструмент, который останется с вами столько, сколько проживёт ваш диск.



















