
За последние 10 лет TSMC вложила почти $240 млрд в расширение мощностей и стала крупнейшим в мире производителем передовых логических микросхем
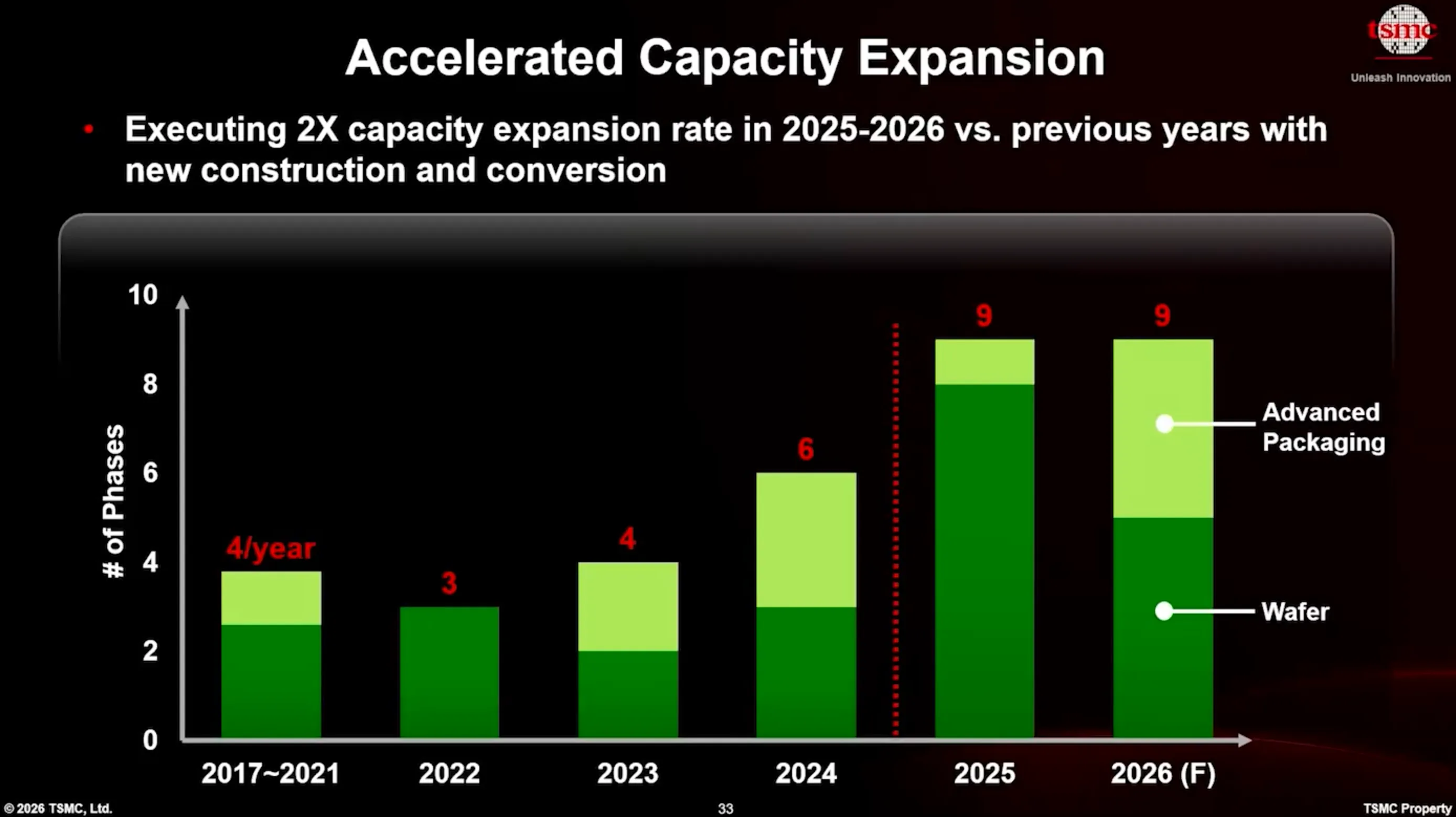
В 2025–2026 годах компания удвоила темпы строительства — до девяти очередей фабрик в год, одновременно разворачивая производство на Тайване, в США, Японии и Германии
Запуск техпроцесса N2 сразу на пяти фабриках в первый же год обеспечит мощность 90 000 пластин в месяц — вдвое больше, чем у конкурирующего 18A от Intel
Мощности по корпусированию CoWoS и SoIC будут расти с темпом 80% и 90% в год вплоть до 2027 года, а внедрение оптимизации на основе ИИ ускорило валидацию нового оборудования на 20%
Ещё несколько лет назад TSMC называли «крупнейшим контрактным производителем» — с оговоркой, что Intel по-прежнему остаётся крупнейшим в мире изготовителем передовых логических микросхем. Но потратив за последнее десятилетие почти $240 млрд на расширение, TSMC теперь располагает девятью площадками с десятками 300-мм фабрик. Многие из них способны обрабатывать на порядки больше пластин по EUV-технологиям, чем Intel*, и именно это делает TSMC крупнейшим в мире производителем передовых чипов.
 Источник изображения — Getty Images / Jimmy Beunardeau
Источник изображения — Getty Images / Jimmy Beunardeau
Как крупнейшему в мире изготовителю передовых процессоров для ИИ, TSMC приходится опережать конкурентов — Intel и Samsung Foundry — не только по технологическим нормам, но и, что, пожалуй, важнее, по производственным мощностям. Ради этого компания запустила самое агрессивное расширение производства в своей истории, стремясь покрыть взрывной спрос на чипы для ИИ, логику по передовым нормам и современные методы корпусирования.
Девять очередей фабрик в год: удвоение исторического темпа
На презентациях в рамках Tech Symposium 2026 компания раскрыла, что в 2025–2026 годах фактически удвоила свой исторический темп строительства, возводя или модернизируя девять очередей фабрик в год против привычных четырёх. Заводы строятся и запускаются одновременно на Тайване, в США, Японии и Германии. Параллельно компания осваивает новые способы выжать больше производительности из уже работающих площадок.
N2: пять фабрик в первый же год
Центральным элементом плана расширения стал техпроцесс N2. Сейчас компания наращивает выпуск чипов по N2 на двух площадках: Fab 20 (очереди 1 и 2) в Синьчжу, рядом с глобальным R&D-центром TSMC, и Fab 22 (очередь 1) в Гаосюне. Запуск передового техпроцесса сразу на нескольких объектах — крайне редкое явление для контрактных производителей. До конца года планируется ввести в строй Fab 22 (очереди 2 и 3), а затем и Fab 22 (очередь 4). В итоге TSMC рассчитывает начать массовое производство по N2 на пяти объектах уже в первый год — беспрецедентный масштаб.
Благодаря такому агрессивному развёртыванию компания ожидает, что объём выпуска пластин по N2 в первый год окажется на 45% выше, чем по N3B. Судя по отчётам за 2023–2024 годы, выпуск N3B стартовал на двух-трёх очередях Fab 18 в 2023 году и к концу года достиг примерно 60 000 стартов пластин в месяц. Если эти оценки верны, то мощность N2 к концу года должна выйти на уровень около 90 000 стартов пластин в месяц. Это превышает максимальную мощность Fab 52, рассчитанной на техпроцесс Intel 18A, которая, по имеющимся данным, составляет порядка 40 000 пластин в месяц.
Ещё более показательно то, что мощности под N2/A16 компания намерена наращивать на 70% ежегодно вплоть до 2028 года, а это означает сотни тысяч пластин в месяц уже к 2029 году.
Почему пять очередей запускают одновременно
Помимо выхода на огромные объёмы, одновременный запуск пяти очередей фабрик помогает снижать риски. Если на одной из них случится загрязнение, отказ оборудования или проблемы с выходом годных, вся цепочка поставок N2 не рухнет. То же касается и производства на двух площадках в разных частях страны: землетрясение или перебой с электричеством могут остановить выпуск или ударить по выходу годных на одной из них, но не затронут другую. Такое распределение рисков критически важно, когда клиенты вроде Apple, AMD, Nvidia или Qualcomm требуют бесперебойных поставок. Есть у параллельного, а не последовательного запуска и ещё один потенциальный бонус — о нём ниже.
«Одна команда» и Super Manufacturing Platform
Столь необычная стратегия запуска, судя по всему, стала возможной благодаря двум программам TSMC: коллаборации «Одна команда» между R&D и производством, а также платформе Super Manufacturing Platform (SMP), которая позволяет нескольким фабрикам (точнее, очередям фабрик) работать как единое целое — вероятно, с идейным сходством с подходом «Copy Exactly» от Intel. Подробностей компания почти не раскрывает, но кое-какие обоснованные предположения сделать можно.
«Одна команда» — это глобальная система передачи производственных знаний, связывающая R&D, интеграцию процессов, управление оборудованием и опыт массового производства на всех этапах разработки и запуска технологии. Чтобы ускорить циклы обратной связи, TSMC, по-видимому, подключает производственные команды довольно рано — ещё на стадии разработки узла, чтобы R&D ориентировались на реальные возможности фабрик. В результате наработки по выходу годных, оптимизации процессов и производительности оборудования можно быстро отладить на одной фабрике, а затем передать остальным. По данным компании, «Одна команда» ускорила передачу технологии на 20% по сравнению с N3 (правда, без указания, сколько времени обычно занимает такая передача).
Кроме того, все площадки GigaFab теперь опираются на платформу SMP — по сути, централизованную систему управления производством, которая заставляет несколько фабрик работать как одна гигантская синхронизированная фабрика: с едиными рецептами процессов, конфигурациями оборудования, метрологией и потоками управления выходом годных. Это должно позволить компании легче перераспределять производство между фабриками, быстрее запускать новые узлы, внедрять исправления по выходу годных глобально, а не локально, и сокращать переаттестацию у клиентов при переносе выпуска чипов с одной фабрики на другую.
Более того, поскольку каждая очередь фабрики генерирует собственные данные о поведении оборудования, плотности дефектов, технологическом окне и обучении по выходу годных, одновременный запуск нескольких очередей при наличии SMP и «Одной команды» может на деле ускорять это обучение. А значит — и ускорять ввод очередей в строй.
Темп роста мощностей N2/A16 в 70% в год в ближайшие годы — это чрезвычайно агрессивное развёртывание для передового производства. Без чего-то вроде «Одной команды» и SMP координировать расширение такого масштаба на нескольких очередях Fab 22, Fab 20 и, в перспективе, Fab 21 (очередь 3) в Аризоне было бы практически невозможно — ни организационно (операционный контроль), ни экономически (обучение по выходу годных, технологическое окно и т. д.).
Компания также отметила, что, несмотря на заметно более высокую сложность транзисторов GAA (gate-all-around) с нанолистами, N2 демонстрирует лучшую кривую обучения по выходу годных, чем N3 — что снова объясняется применяемыми инновационными подходами.
Что будет после N2: A14, A13, A12 и новая Fab 25
Производство по техпроцессам N2/N2P/N2X/N2U/A16 будет в основном сосредоточено на Fab 20 (очереди 1 и 2), Fab 22 (очереди 1–4) и отчасти на Fab 21 (очередь 3). А вот для узлов следующего после 2-нм класса — таких как A14, A13 и A12 (напомним, A16 — это, по сути, N2P с тыловой системой подачи питания) — TSMC построит Fab 21 (очередь 3), а затем и совершенно новую площадку Fab 25 в центральной части Тайваня, как минимум с четырьмя очередями.
 Источник изображения — TSMC
Источник изображения — TSMC
Массовое производство A14 должно стартовать в конце 2028 года, так что велика вероятность, что компания запустит его сразу на Fab 20 (очередь 3) и Fab 25 (очередь 1). Впрочем, учитывая агрессивный подход к расширению, TSMC вполне может снова всех удивить. Пока неизвестно и то, планирует ли компания модернизировать фабрики, рассчитанные на N2/A16, под последующие узлы — если планирует вообще.
N3 и N5: конвертация мощностей и роль ИИ
Расширение не ограничивается N2 и более новыми технологиями. Совокупные мощности N3 и N5 компания наращивает со среднегодовым темпом 25% в период с 2022 по 2027 год. Чтобы покрыть текущий спрос, часть мощностей N5 переводится под выпуск N3 — это не особенно дорого, поскольку N3 повторно использует 85–90% оборудования от N5. К тому же значительная доля мощностей N3 и N5 сосредоточена на одной площадке — Fab 18 (четыре очереди N5 и четыре очереди N3), так что конвертация относительно проста с точки зрения логистики.
Параллельно с конвертацией N5 в N3 компания активно использует ИИ для повышения производительности как отдельных установок, так и фабрики целиком. По сути, TSMC применяет ИИ, чтобы делать больше чипов для ИИ — звучит парадоксально, но становится нормой по мере проникновения ИИ в рабочие процессы.
Одна из главных причин, замедляющих производственный цикл современных фабрик, — пакетная обработка пластин в разных камерах, неизбежная часть примерно 5000 технологических этапов. Грубо говоря, 25 пластин «ждут» (скажем, в CVD-камере), пока литографическая установка обрабатывает их по одной.
Ацуёси Койке из Rapidus придерживается иного взгляда: он считает, что поэтапная обработка по одной пластине на всех этапах может заметно сократить время цикла, пусть и ценой эффективности использования оборудования. TSMC, похоже, переходить на обработку одиночных пластин не собирается (хотя при её покупательной способности убедить производителей оборудования выпустить нужные установки наверняка реально), но точно может оптимизировать использование уже имеющегося парка ради большей отдачи действующих фабрик.
На недавнем Technology Summit компания раскрыла, что применяет интеллектуальные системы планирования с «современными алгоритмами линейного программирования и эвристическими методами» для оптимизации эффективности оборудования — правда, без уточнения, что именно делается и какого результата удаётся достичь. Используются и генеративные алгоритмы ИИ для подбора оптимальных параметров, которые «бросают вызов физическим пределам оборудования», сохраняя при этом качество пластин. Параллельно журналы работы установок анализируются средствами аналитики больших данных и интеллектуального разбора текста — ради динамической подстройки ключевых параметров, минимизации простоев и максимизации выпуска.
Системы ИИ анализируют состояние камер в реальном времени, чтобы определить оптимальный момент для их очистки и избежать лишнего обслуживания, снижающего время безотказной работы и доступную мощность. Кроме того, автоматизированное сравнение и тонкая настройка больших объёмов параметров верификации установок с помощью ИИ позволили сократить время на валидацию нового оборудования и выход на массовое производство более чем на 20% — это помогает быстрее вводить новые производственные модули.
Наконец, на Fab 18 в Тайнане компания добилась более гибкого распределения и более высокой совокупной мощности N3 и N5 за счёт повышения универсальности оборудования и «кросстехнологического планирования» — то есть максимально возможного повторного использования установок под разные процессы.
География: Аризона, Япония и Германия
За пределами Тайваня TSMC продолжает расширять присутствие. В Аризоне Fab 21 (очередь 1) уже выпускает чипы по техпроцессу N4, причём мощность в этом году вырастет в 1,8 раза, а Fab 21 (очередь 2) должна запустить N3 в третьем квартале 2027 года. Fab 21 (очередь 3) нацелена на N2 ближе к концу десятилетия — компания продолжает возводить корпуса под очереди 3 и 4. Подтверждены также планы по строительству предприятия передового корпусирования, R&D-центра и приобретению дополнительной земли под будущее расширение.
В Японии Fab 23 (очередь 1) в Кумамото уже выпускает чипы по нормам 28 нм и 22 нм, а вот Fab 23 (очередь 2) пережила серьёзную стратегическую перестройку. Изначально её готовили под 7-нм класс, но вместо этого она будет выпускать продукцию вплоть до N3 (3 нм) — ради более сильного, чем ожидалось, местного спроса и стремления японских разработчиков чипов локализовать производство.
Тем временем строящаяся Fab 23 в Дрездене (Германия) ориентирована на автомобильные и промышленные применения — на устаревших планарных транзисторах и FinFET-нормах 28 нм, 22 нм, N16 и N12.
ИИ как главный драйвер и взлёт передового корпусирования
Сам ИИ сегодня — один из главных двигателей беспрецедентного роста мощностей компании. По данным TSMC, поставки пластин для ИИ-ускорителей с 2022 по 2026 год должны вырасти в 11 раз. Отдельно компания отметила быстрый рост числа очень крупных кристаллов площадью свыше 500 мм²: за тот же период их поставки, по прогнозам, увеличатся в 6 раз. Такие изделия обычно требуют больших мощностей по обработке пластин и передовых технологий корпусирования, ведь многие из этих решений используют память HBM3E.
Поэтому передовое корпусирование стало не менее важным, чем само производство пластин. Мощности CoWoS будут расти со среднегодовым темпом 80% в период с 2022 по 2027 год, а мощности SoIC за тот же срок — со средним темпом 90%. При этом компания сократила время перехода от разработки к массовому производству на 30% для CoWoS и на 75% для SoIC по сравнению с предыдущими поколениями.
Сейчас TSMC управляет 11 предприятиями передового корпусирования на Тайване (AP1 в Синьчжу; AP2A/AP2B/AP2C и AP8 в Тайнане; AP3 в Лунтане; AP5 в Тайчжуне; AP6A/AP6B/AP6C в Чжунане; AP7 в Цзяи). По недавнему отчёту DigiTimes, компания одновременно расширяет сразу несколько кампусов корпусирования — AP5, AP6, AP7 и AP8.
Площадка AP7 в Цзяи, как сообщается, станет крупнейшим кампусом передового корпусирования TSMC и будет использовать SoIC для поддержки таких клиентов, как Nvidia, планирующая применить технологии 3D-корпусирования в графических процессорах Feynman следующего поколения. Ожидается, что AP8, переоборудованная из бывшего LCD-завода Innolux, к концу 2026 года превысит 40 000 пластин CoWoS в месяц.
Если CoWoS уже стал де-факто стандартом для процессоров ИИ, то SoIC в ближайшие годы должна получить гораздо более широкое распространение. Поэтому компания быстро наращивает и мощности SoIC. По данным DigiTimes, AP6 в Чжунане может приблизиться к 10 000 пластин SoIC в месяц, а AP7B — добавить ещё около 12 000 пластин в месяц. Будущие очереди AP7, как ожидается, будут поддерживать и SoIC, и CoPoS — хотя последняя относится уже к дорожной карте TSMC на 2030-е годы.
Передовое корпусирование теперь требует тесной интеграции целой экосистемы: поставщиков HBM, изготовителей подложек, OSAT-партнёров, испытательных компаний, поставщиков материалов и производителей оборудования, с которыми TSMC работает над стандартизацией установок. Само появление такой экосистемы подчёркивает растущую роль компании в стремительно развивающейся индустрии ИИ.
Итог: от крупнейшего контрактного производителя к лидеру передовой логики
Вложив за десятилетие почти $240 млрд в расширение мощностей, TSMC превратилась из крупнейшего в мире контрактного производителя в крупнейшего в мире изготовителя передовых логических микросхем, выпуская львиную долю современных процессоров для ИИ.
Чтобы покрыть взрывной спрос на ИИ и опередить Intel и Samsung Electronics, компания удвоила исторический темп строительства до девяти очередей фабрик в год в 2025–2026 годах, одновременно расширяясь на Тайване, в Аризоне, Японии и Германии. Запуск N2 беспрецедентен: пять очередей фабрик в течение первого года жизни узла, а мощности N2/A16, по прогнозам, будут расти на 70% в год вплоть до 2028 года.
По словам компании, столь агрессивное расширение стало возможным благодаря организационной структуре «Одна команда» и платформе SMP, синхронизирующей производство, обучение по выходу годных и контроль процессов на нескольких фабриках. Параллельно внедряются различные оптимизации на основе ИИ — интеллектуальное планирование, настройка процессов генеративным ИИ и аналитика оборудования в реальном времени — ради роста пропускной способности, сокращения времени цикла и ускоренной аттестации установок. И одновременно компания стремительно расширяет мощности передового корпусирования: CoWoS и SoIC будут расти на 80% и 90% в год к 2027 году, по мере того как чиплетные конструкции и память HBM становятся предпочтительными технологиями для ИИ-ускорителей.
* Для масштаба: выручка TSMC от обработки пластин за 2025 год составила около $103,7 млрд — порядка 84% консолидированной выручки в $122,4 млрд. EUV-техпроцессы N3 и N5 принесли 60% выручки от продажи пластин, то есть примерно $62,2 млрд. Для сравнения: Intel Foundry заработала в 2025 году $17,826 млрд, из которых лишь $307 млн пришлись на внешних клиентов, в основном заказывавших передовое корпусирование. По оценкам, на EUV-техпроцессы приходится более 10%, но менее 20% выручки Intel от пластин. Intel не раскрывает разбивку выручки по аналогии с TSMC (пластины / корпусирование и тестирование / прочее), поэтому её выручку от обработки пластин оценить трудно — тем более что часть кремния Intel производит как раз на TSMC, а корпусирует уже у себя. Тем не менее даже 20% выручки Intel Foundry за 2025 год — это $3,565 млрд, что более чем в 17 раз меньше, чем TSMC зарабатывает на одних только EUV-узлах.


















