
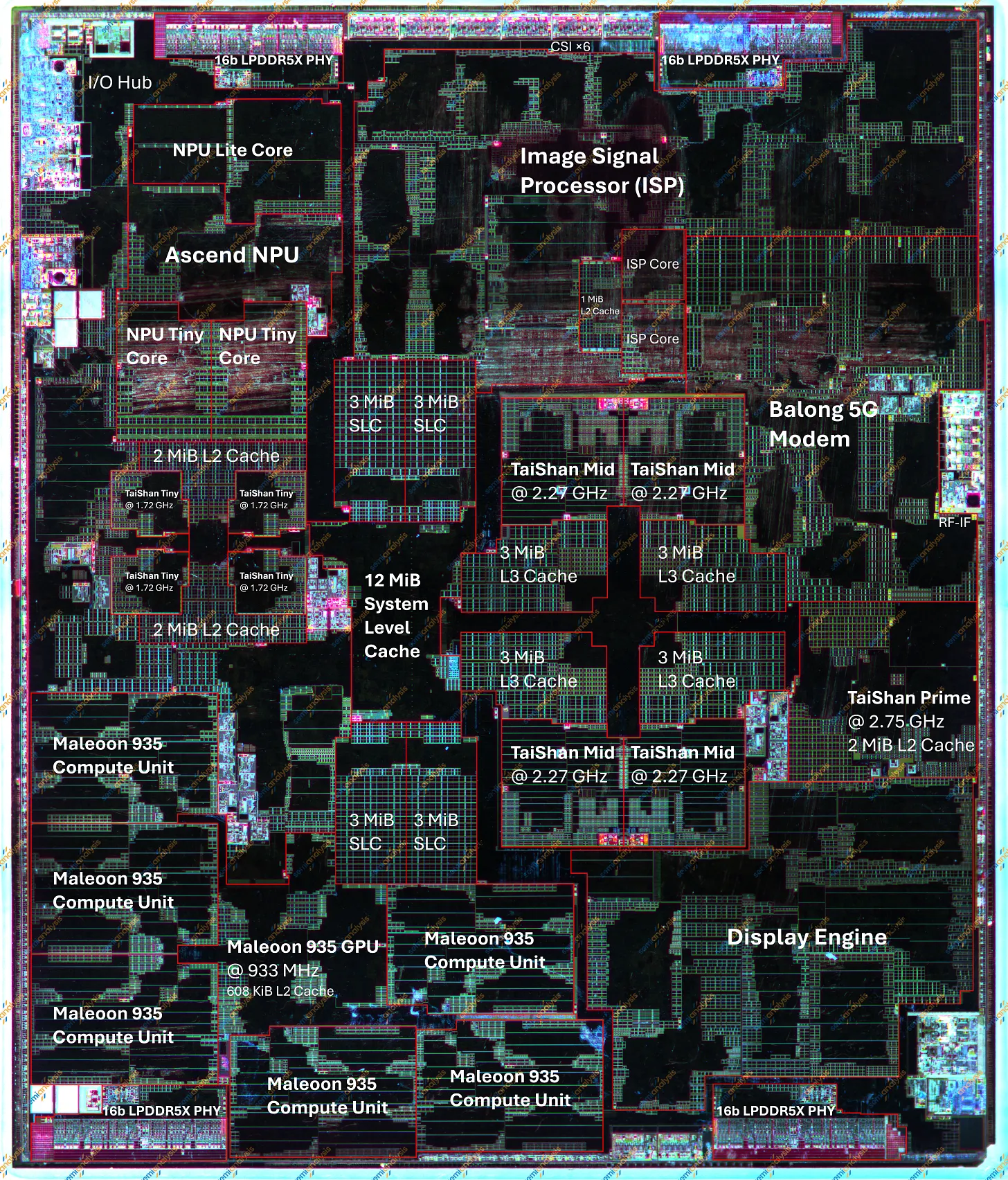
Минимальный шаг металлизации SMIC N+3 — 32,5 нм, плотнее, чем 36 нм у Intel 18A в Panther Lake, но это «вишенка на торте»: по итоговой плотности транзисторов китайский техпроцесс отстаёт на 38%
7-нм процесс N+3 без EUV-литографии достигает 113,4 млн транзисторов на мм² — на уровне зрелого TSMC N6, но ценой резко возросшей сложности и стоимости
Kirin 9030 Pro по производительности на такт держится на уровне Android-флагманов трёхлетней давности и отстаёт от Apple M5 в 2,7 раза
SemiAnalysis открыла собственную лабораторию STEEL в Орегоне, бросив вызов монополисту обратного инжиниринга TechInsights
Аналитическая фирма SemiAnalysis опубликовала первый разбор, выполненный в её новой собственной лаборатории, — и сразу с громким заголовком. Минимальный шаг локальной металлизации на третьем поколении 7-нм техпроцесса SMIC (N+3) составил 32,5 нм. Это плотнее, чем 36 нм, которые Intel применяет в процессорах Panther Lake на техпроцессе 18A. Иными словами, китайская фабрика без доступа к EUV-сканерам формально превзошла по этому параметру передовой западный узел. Однако сами аналитики тут же оговариваются: цифра верна, но это тщательно подобранный, неполный показатель. По итоговой плотности транзисторов N+3 уступает библиотеке высокой плотности Intel 18A на 38%.
Анализ провели на процессоре HiSilicon Kirin 9030, который устанавливается в смартфоны серии Huawei Mate 80 и выпускается по технологии N+3. Лаборатория SemiAnalysis Teardown Engineering & Evaluation Lab (STEEL) расположена в Хилсборо, штат Орегон, и нацелена на конкуренцию с канадской TechInsights в области обратного инжиниринга передовых техпроцессов.
 Источник изображения — Getty / Bloomberg
Источник изображения — Getty / Bloomberg
Почему 32,5 нм у SMIC «обгоняют» 36 нм у Intel — и почему это обманчиво
Прежде чем делать выводы, стоит пояснить термин. Шаг металлизации — это расстояние от центра одного проводника до центра соседней металлической дорожки, то есть сумма минимальной ширины дорожки и минимального зазора между дорожками. Это один из ключевых индикаторов того, насколько плотно можно «упаковать» транзисторы.
В чипах Panther Lake используется шаг 36 нм, хотя сам техпроцесс 18A поддерживает минимум в 32 нм. Intel намеренно увеличила шаг: маршрутизация питания через обратную сторону пластины (технология PowerVia, то есть «тыловое питание») освобождает лицевую сторону кристалла под сигнальные линии. По заявлениям самой Intel, такой подход даёт примерно 10% прироста плотности и позволяет ослабить требования к шагу на лицевой стороне.
Именно поэтому узел на базе транзисторов GAA RibbonFET и тылового питания может позволить себе более широкий локальный шаг, чем китайский DUV-процесс, и при этом сохранять значительное общее преимущество. Проще говоря, Intel может рисовать дорожки реже, потому что выжимает плотность другими, более продвинутыми способами.
 Источник изображения — SemiAnalysis
Источник изображения — SemiAnalysis
Какой ценой даётся плотность без EUV
SMIC удалось достичь 32,5 нм без EUV-литографии, опираясь на DUV-оборудование и многократное экспонирование. Для самого критичного слоя металлизации (M0) применяется самосовмещённое четырёхкратное экспонирование (SAQP), которое требует дополнительных масок и этапов травления. Для сравнения, TSMC на сопоставимых узлах обходится более простым двукратным экспонированием (SADP). Аналитики отмечают, что у SAQP более сложный контроль процесса и трапециевидный профиль траншеи: это помогает заполнению медью, но резко усложняет производство.
Образная аналогия, которую приводит SemiAnalysis: SMIC печатает «банкноты» того же номинала, что и TSMC, но себестоимость каждой «банкноты» в несколько раз выше.
При подсчёте итоговой плотности транзисторов SemiAnalysis оценила N+3 в 113,4 млн на квадратный миллиметр — лишь немного выше зрелого TSMC N6 (107,7 млн) и значительно ниже 18A. SMIC добилась этого, задействовав все доступные без EUV приёмы повышения плотности и так называемую совместную оптимизацию проектирования и технологии (DTCO): два «плавника» (fin) на транзистор, контакты, расположенные непосредственно над активным затвором, и одинарные разрывы диффузионных областей между ячейками. Любопытно, что и TSMC при переходе с N7 на N6 нарастила плотность не за счёт более тонких шагов, а именно благодаря DTCO.
Каждый из этих обходных путей увеличивает сложность и стоимость, и достигнутый потолок N+3 наглядно показывает масштаб компромисса. Сами в SemiAnalysis уточняют классификацию: это не полноценный 5-нм узел, а нечто промежуточное между 7 нм и 5 нм.
Что это значит для реальной производительности смартфонов
Технологические компромиссы напрямую сказываются на быстродействии. Основное ядро Kirin 9030 Pro (архитектура TaiShan Prime) работает на частоте 2,75 ГГц, а по производительности на такт (IPC) приближается к Arm Cortex-X2 образца 2021 года. Это ставит чип примерно на уровень флагманов Android трёхлетней давности и позади текущих решений Apple, Qualcomm, MediaTek и Samsung. Для наглядности: ядро Apple Firestorm из M1 (2020 год) сохраняет преимущество в IPC около 35%, а новейшее P-ядро Apple M5 опережает по IPC на 60%, что в абсолютных значениях даёт разрыв в 2,7 раза.
Графика выглядит чуть бодрее: видеоядро Maleoon 935 примерно соответствует флагманам 2022 года, слегка обходя Snapdragon 8+ Gen 1 и Apple A16 в отдельных тестах, но всё равно отстаёт от современных Snapdragon 8 Elite Gen 5 и Dimensity 9500 в 2,4–2,6 раза.
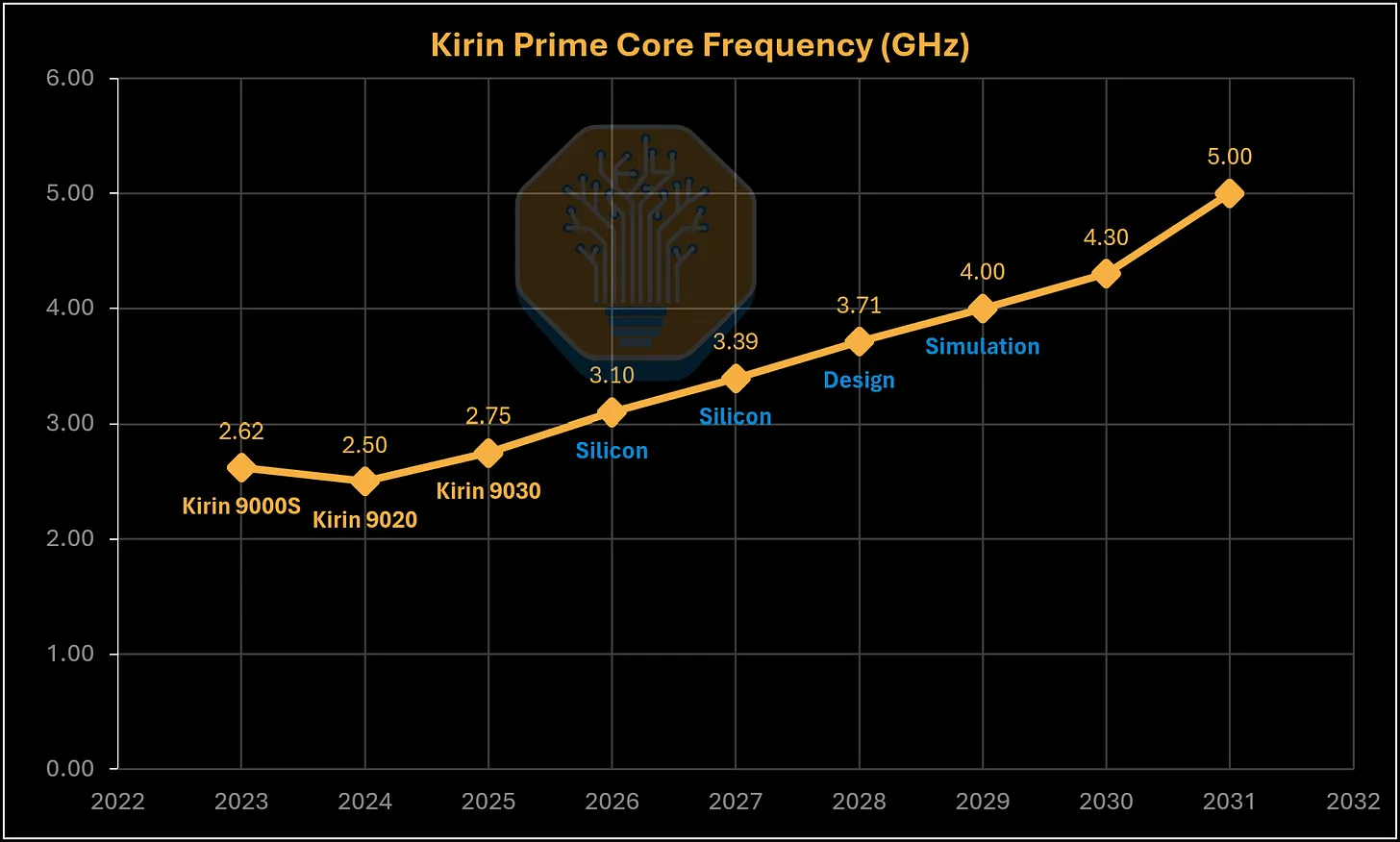
Дорожная карта Huawei ставит цель в 5 ГГц к 2031 году, но, как отмечает SemiAnalysis, это «далеко за пределами того, что может дать простое масштабирование планарных транзисторов». Ответом компании должна стать архитектура LogicFolding — вертикальное 3D-стекирование логических блоков, призванное компенсировать нехватку плановой плотности и сократить длину сигнальных путей. По сути, упёршись в потолок литографии без EUV, китайская индустрия делает ставку на «складывание» чипов в третьем измерении. Под эту концепцию в Китае уже разрабатываются и собственные средства автоматизированного проектирования (EDA).
 Источник изображения — Huawei, SemiAnalysis
Источник изображения — Huawei, SemiAnalysis
Память: китайские компоненты вперемешку с Samsung
Вскрытие также показало, что Kirin 9030 Pro использует память Samsung LPDDR5X: в версии на 12 ГБ обнаружены два стека по четыре кристалла Samsung (1a-узел, LPDDR5X-9600), производимые серийно с 2022 года. А вот в варианте на 16 ГБ найдена DRAM китайского производителя CXMT (узел G4). Это показательная деталь: даже флагман, который преподносится как символ технологической независимости, всё ещё опирается на иностранные компоненты, постепенно замещая их отечественными.
Зачем SemiAnalysis собственная лаборатория и удар по TechInsights
На рынке обратного инжиниринга чипов десятилетиями доминировала TechInsights из Оттавы. Теперь SemiAnalysis заходит на её территорию напрямую. Компания сообщила, что потратила около 18 месяцев и десятки миллионов долларов на оборудование, и лаборатория уже окупается за счёт анализа датацентровых чипов — в частности, упоминается разбор 3D-стека оптического движка COUPE CPO и EIC крупного клиента TSMC.
Момент для выхода выбран не случайно. По утверждению SemiAnalysis, конкурент из Оттавы, принадлежащий частным инвестиционным фондам (включая Oakley Capital и CVC Growth), выставлен на продажу и из-за этого недоинвестировал в оборудование — официального подтверждения этому, впрочем, нет. SemiAnalysis при этом подчёркивает, что за шесть лет существования без венчурных и фондовых вложений уже обгоняет TechInsights по выручке, а потому может позволить себе быстрее обновлять парк техники и регулярно выкладывать часть разборов бесплатно.














